Previous: Color Models
Up: Related Work
As outlined in the introduction, the working hypothesis of this dissertation is that the characteristics of the underlying neurophysiological color vision process explain phenomena like the universality of basic color category foci and graded membership of color samples in color categories. In other words, both universal basic color foci and graded membership properties must follow directly from the properties of the used color model, if we want the color model to explain human color naming behavior. It is not sufficient for a color model to merely categorize all possible color percepts in a systematic way; it must also explain why some color percepts are more salient than others, and why category membership judgments are graded. I hypothesize that when learning basic color names, some points in the learning space are more salient than others and act as ``attractors'' for category foci. These properties must follow from the color model, and it is against these criteria that I will judge the usefulness of any particular color model. None of the existing color models meets these criteria.
In the light of the requirements for color vision models set forth above, we can immediately disqualify a number of simplistic models of color naming that might be intuitively appealing:
From a psychological point of view, the inappropriateness of RGB as a color
model is clearly demonstrated by the difficulty people experience in
manipulating RGB color coding in a consistent and intuitive way, and by the
recent interest in different kinds of color models (among which are
opponent models) in computer graphics research
[Scheifler \& Gettys 1992][Robertson \& O'Callaghan 1986][Turkowski 1986][Rogers 1985][Naiman 1985][Meyer \& Greenberg 1980].
[Rogers 1985] points out that RGB and all of the linear transforms thereof
(CIE XYZ, YIQ, CMY) are difficult for users to specify subjective color
concepts in. A closer look at the properties of RGB representations
provides independent evidence. The RGB color solid has the shape of a unit
cube, with the achromatic (grey level) dimension going from to
, and the maximally saturated colors
red, green, and blue at a lower brightness level than the maximally
saturated colors yellow, cyan, and purple, all of which are situated at
corners of the cube (Figure
).
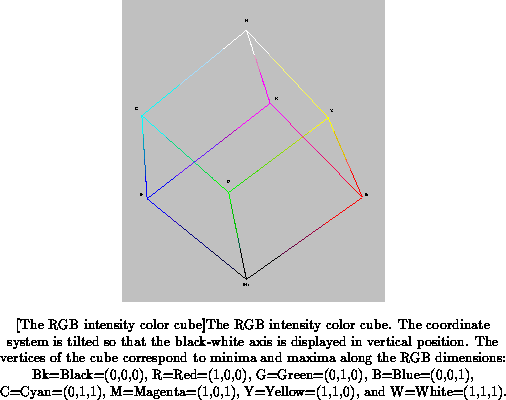
This kind of organization does not match the color naming data very well. As [Shepard 1987] points out, the representation of stimulus data is of major importance for the interpretation of experimental psychological results. He cites the example of generalization across stimuli, which can exhibit a non-monotonic increase between stimuli separated by certain special intervals in a metric space, for example, between tones separated by an octave, between hues at opposite ends of the visible spectrum (red and violet), and between shapes differing by particular angles related to inherent symmetries of those shapes. If we use a circular hue representation rather than a wavelength interval representation, as in the Munsell color space, for instance, red and violet become neighbors rather than opposites, and the apparent nonmonotonic effect disappears. Similar conceptions of psychological spaces exist for pitch [Patterson 1986] and shape [Walters 1987].
The same holds, mutatis mutandis, for lookup tables specifying RGB values indexed by color names (as found in the X-windows system, for instance), or the other way around. This kind of ``model'' does not even provide a name for every point in the space, and graded membership or learning names in a productive way is even harder to model in this context, not to mention the existence of universal color foci.
Other kinds of existing color models (CIE chromaticity, opponent models, psycho-physical and colorimetric models in general) all suffer from the same disadvantage of not being able to explain the existence of universal foci, and to a lesser extent, the graded category membership functions.
The only existing models of color naming based explicitly on the neurophysiology of color vision and attempting to explain the universality of foci and graded membership functions are [Cairo 1977] and [Kay \& McDaniel 1978]. Apart from not being defined or implemented as full-fledged computational models, both of these have important drawbacks. Kay and McDaniel's model interprets (stylized versions of) the response functions of four types of color-sensitive cells in the LGN [De Valois et al. 1966] as characteristic functions of four fuzzy sets corresponding to the categories red, green, yellow, and blue. As such, the model explains the existence of universal foci (which correspond to maxima of the characteristic functions) and the graded membership functions (which correspond directly to the characteristic functions) of these four basic color categories. But the model has to be tweaked to account for other basic color categories (requiring the introduction of new and ad hoc fuzzy set operations and a nonlinear compression of the wavelength dimension that is without apparent external motivation), and it is not clear at all how non-spectral basic color categories like brown or purple are to be dealt with, nor how to model the learning of color names in this model. It also does not adequately explain the hierarchy of languages with respect to the lexical encoding of basic color categories. Another objection that can be brought against the model is that it predicts that a flat-spectrum white stimulus light is a good example of every basic color category, since there is no opponent mechanism that cancels out opponent primaries. This prediction is clearly not born out by experience or by psychophysical experimentation.
Cairo's model of color naming [Cairo 1977] is also based on findings in the physiology of the pre-cortical visual system. It is four-dimensional: wavelength, intensity, purity, and a fourth dimension representing the adaptation state of the retina. All of these dimensions are defined as physical parameters of the stimulus, rather than as perceptual dimensions. Cairo introduces a ``data-reduction model'' of analog-to-digital conversion in the pre-cortical visual system, and represents Berlin and Kay's eleven basic color categories as specific combinations of quantized values on the four dimensions. In addition, he predicts four potential new basic color categories beyond Berlin and Kay's eleven, which he calls sky-blue, turquoise, lime, and khaki.
Although this model is interesting for its attempt to take adaptation into
account, it suffers from a number of important drawbacks. For instance, the
discrete nature of the model and the use of wavelength as one of the
dimensions forces complex stimuli to be treated as if they were
monochromatic, and this is done using the ``dominant wavelength'' to
represent an entire spectrum. While this may work in limited
circumstances, it is clearly a gross simplification which cannot hold in
general (e.g., which is the ``dominant wavelength'' of the spectra of
Figure ?). In addition, Cairo claims that Berlin and Kay's
finding of universal foci of categories is a mere artifact introduced by
the use of the Munsell color system for the stimulus material used in the
experiment. This conclusion does not seem to be supported by the wealth of
psychological and linguistic research done since Berlin and Kay's initial
study (cf. the bibliography of recent research in [Berlin \& Kay 1969]). On the
contrary, it seems that it is rather Cairo himself who is forced to deny
the evidence because of the discrete nature of his model, which does not
allow for graded categories. The discretization of the model itself seems
to be fueled by a desire to make color notation the subject of algebraic
analysis, requiring a complete ordering of a discrete number of possible
color values. While that may be a noble cause, it also requires most of the
data on actual color naming behavior to be ignored, which is too much of a
price to pay for a convenient analysis. Berlin and Kay's hierarchy of
languages is explained in a rather circular fashion by Cairo in terms of
the ``perceptual salience'' of the four underlying dimensions, but without
explaining where their salience derives from. In general, this model seems
overly biased by an extreme information processing view of psychology that
regards cognition quite literally as a digital computational
process.
[Harnad et al. 1991] present a rather different approach to the categorization problem, using artificial neural networks. They consider the problem of separating lines into two classes. After training an auto-associator network (one that essentially reproduces its input as its output), they add a categorization task to the same net. The result is that the ``similarity space'' derived from the net's hidden nodes' activations is warped to reflect categorial boundaries. The analysis of the network representations is interesting, and the authors provide a good discussion of network representations, but the applicability of the approach seems limited. An interesting thing to note is that the representations used by this network seem just as ungrounded as the symbolic representations that the first author criticizes in some of his other work [Harnad 1990].