Previous: Psycho-Physical Variables
Up: From Visual Stimuli to Color Space
Now that we have constructed the NPP space, we need to be able to transform
data coming from color sensors (typically an RGB color camera) into it, if
we want the NPP space to be usable for robotic agents
(Chapter p.
) or for general
computer vision work. Since all color cameras in use today are based on the
CIE XYZ standard, we need to transform XYZ coordinates to NPP
coordinates. This will proceed in two steps: a transform from XYZ to the 6
linear functions from Section
(p.
),
followed by sigmoidification and a final linear transform to make the gray
axis vertical, as described in the same section. Although it might be
possible in principle to go directly from XYZ to NPP coordinates, I have
chosen the method just described because it follows the theoretical
construction of the NPP space more closely, and it provides additional
advantages for the learning (optimization) procedure described
below.
Since it is not possible to determine a simple linear transform from XYZ to
the 6 linear functions within a reasonable margin of error, I have used the error
back-propagation algorithm to determine such a transform, as commonly used
in artificial neural networks research [Rumelhart et al. 1986]. In contrast with
many applications of the backpropagation technique I did not use the
network as a classifier, but rather to learn six simultaneous functions of
three real variables (the CIE X, Y, and Z coordinates), implementing a
transform from one space to another. Using the networks this way imposes
much stricter requirements on the obtained transform than using them as a
classifier does, since both the domain and range are continuous-valued, and
there are no ``bins'' in the range within which differences in function
values are not important, as is the case in classifier nets.
The error back-propagation algorithm is defined for N-layer feed-forward networks with consecutive
layers fully connected, no connections going to nodes in layers other than
the neighboring one(s), and using the sigmoid node activation function
(Figures
and
).


Since this kind of network is strictly feed-forward, the computation at each layer amounts to the composition of a linear transform with the sigmoid node activation function:
where represents the weight matrix for stage
,
represents the vector of inputs to this stage, i.e., the activations of the
nodes at stage
,
represents the vector of outputs of this
stage, i.e., the activations of the nodes at stage
, and
represents
the usual sigmoid activation function from equation
(p.
). After the network has been trained we
can collect the matrices
and implement the transform via
equation
, disregarding the neural network simulation
machinery. If we keep the networks ``rectangular'', i.e., with the same
number of nodes at each layer, we can also determine the inverse transform
by inverting the matrices
(if possible) and the sigmoid
function
. This turns out to be possible for the transforms I have
computed, so I have indeed used rectangular nets, padding the input and/or
output with small fixed random values if necessary. This padding does not
seem to have any noticeable effect on the convergence of the backpropagation
algorithm or the quality of the computed transform (as determined by the
procedure outlined below).
One of the most critical problems in using the error backpropagation algorithm to learn a particular transform is the selection of a proper training set. Since this learning technique is a supervised one, one needs to construct a set of input-output pairs that covers the n-dimensional input and output subspaces (assuming n input and output nodes) sufficiently well to produce a smooth transform, without significant discontinuities and generalizing well to new input/output pairs. In our particular case, the natural thing to do might seem to be to construct a training set based on the pure frequency responses of the XYZ and NPP functions, by varying the frequency over the visible wavelength range:
with symbols as in Section (p.
) and
equation
(p.
). This type of training
set turns out not to work well, and some analysis reveals why: it does not
contain any training points on the gray axis (since no pure frequency
signal results in an equal response of all three XYZ functions) or any
points in the purple region of the color space (since purple is a ``mixture
of red and blue'' which cannot be obtained from a pure frequency signal),
for instance. It is therefore no surprise that the transform does not work
well in these (and other) areas of the color space. What we need to do is
to create a training set containing points corresponding to complex
stimulus spectra, including grays, purples, and all other kinds. Since
spectra can be thought of as real-valued functions of wavelength (usually,
though not necessarily, continuous and differentiable), the set of possible
spectra is infinite. Fortunately we can exploit some constraints on the
physically possible surface reflectance functions to generate a number of
representative spectra, analogous to the way we constructed the OCS surface
in Section
(p.
). We know that all
physically possible spectra must result in points enclosed by that surface
(including points on the gray axis), so these are the spectra of interest
for constructing a training set. Based on the technique described in
Section
(p.
), I have created an extended
one to generate a set of spectra covering both the OCS surface and the
space contained within it. The spectra are given by the following
function:
where is wavelength in nm as usual,
is the width of the
``gap'' in nm,
is the start of the ``gap'' in nm (as in
Section
p.
), and
and
are two reflectance levels in
. By varying
and
over the visible wavelength range and
and
over the
interval, we can generate a subset of all possible reflectance
spectra, some of which are shown in Figure
.
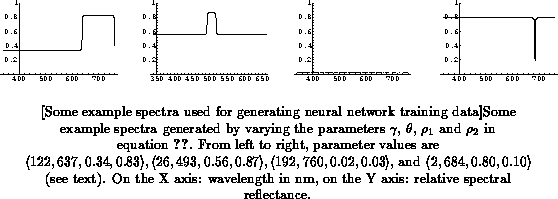
By varying in 10 equal steps from 0 to 400,
in 10 equal
steps from 380 to 780, and
and
each in 7 equal steps from
0 to 1, we obtain a set of 4900 spectra that cover the OCS surface and the
space enclosed by it fairly well, as shown in Figure
.
In this figure the XYZ coordinates corresponding to the spectra are
computed as in equation
(p.
) ff, and these
coordinates are the input values for the training set. The output values
for the training set are computed analogously using the 6 linear NPP
functions.
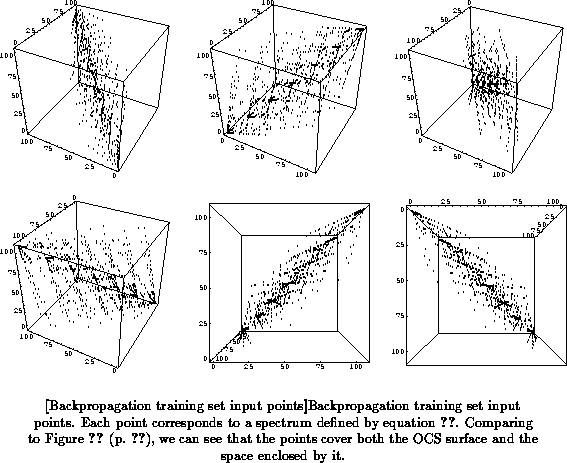
Comparing Figures (p.
) and
we can see that there are no points outside the OCS
surface, which is expected of course. Such points do not correspond to
physically possible reflectance spectra, and hence are of no interest to
us.
As a measure of convergence of the backpropagation algorithm, I have
computed the RMS error vector between the teaching vectors and the output
vectors over the complete training set. The results for two, three, and
four-layer networks are shown in Figure .
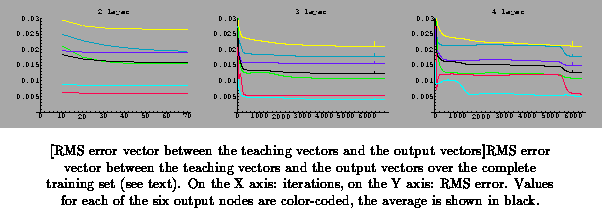
I have used the Rochester Connectionist Simulator for these computations. The
results can be influenced by some additional parameters such as a momentum
term (preventing the weights from changing too abruptly in the course of
learning), a temperature parameter (determining the derivative of the
sigmoid node activation function), and the learning rate (determining how
fast the gradient descent learning proceeds). These parameters were set by
trial and error to 0.66, 0.44, and 0.03, respectively. In general, deciding
when to stop the learning is a relative of the general halting problem, and
thus not a computable function. Since we are doing optimization for one
particular problem, we can hand-pick a local minimum in the error landscape
by examining the error plots over a long enough period, but we can never
really be sure that we have obtained a global minimum. Since the magnitude
of the error derivative tends to approach zero over the course of learning,
we can be reasonably confident that whatever local minimum we pick is not
too far from the global minimum, although networks with more layers tend to
display sudden changes in the error functions, as evident for the 4 layer
network in Figure (between 5000 and 6000 iterations).
Of course the quality of the obtained transform is more important than the
RMS error over the training set. To evaluate this, I will first compare the
position of the gray axis in the NPP space as derived in Section
(p.
) to the gray axis as computed by the network-derived
transforms (Figure
).

Visual inspection reveals that the gray axis extends into the negative
brightness values for the 2-layer network transform, which is of course
undesirable, but not for the 3 or 4-layer transforms. In all cases, the
transformed gray axis is vertical, and somewhat more curved than the
original. The exact black and white coordinates are for the NPP space, and
for the 2-layer network transform,
for the 3-layer, and
for the 4-layer network transform (to 2
significant digits). For 11 equally spaced points along the NPP gray axis,
the RMS error vectors relative to the transformed points are
for the 2-layer net,
for the 3-layer, and
for the 4-layer net, which
confirms the aberration in the brightness dimension for the 2-layer net.
The other two are close enough to make the difference insignificant.
Another important measure of the quality of the transform is what it does
to the OCS surface, which I will continue to use as a frame of reference
for studying the spacing of basic color category foci in the NPP and other
spaces. Figure shows the OCS surface as
transformed by the 4-layer network, the one with the lowest overall RMS
error. It should be compared to Figure
(p.
), which shows the same surface in the
(directly computed) NPP space.
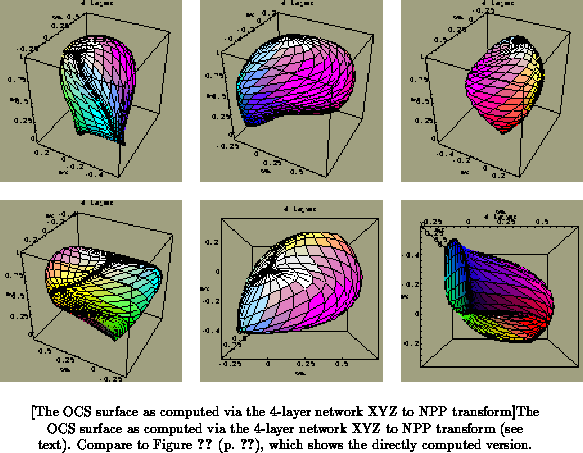
We can see that the general shape of the transformed space
(Figure ) is close to that of the directly computed
space (Figure
p.
), with
a vertical gray axis, similar spacing of hues around the perimeter of the
surface, and comparable overall dimensions. There are some differences too,
e.g. the (approximately) red-purple region of the transformed space is
stretched and seems to bulge more relative to the directly computed
version. All in all, I consider this result satisfactory enough to be used
in practice. We should also be aware that the directly computed version is
based on measurements of the Macaque visual system, and the transformed one
on a transform of human standard observer functions, which may account for
some of the observed differences.
The exact parameters of the transform are given in
Appendix
.