Previous: A physical implementation: the Robot Waiter
Up: Applications
Next: A simulation study: the Mobile Robot Lab
We are interested in modeling behavior generation by agents that function in dynamic environments. We make the following assumptions for the agent:
To cope in dynamic environments, an agent which is resource bound needs to rely on different types of behaviors, for instance, reflexive, reactive, situated, and deliberative behaviors. Reflexive and reactive behaviors are predominantly ``unconscious'' behaviors, situated action may be either ``unconscious'' or ``conscious'', and deliberative actions are predominantly ``conscious'' behaviors. We assume that in general ``conscious'' behavior generation takes more time than ``unconscious'' behavior generation.
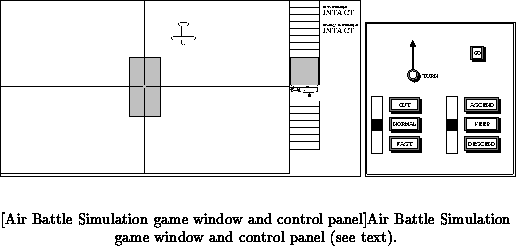
We have written a program, Air Battle Simulation (ABS), that simulates
World War I style airplane dog-fights. ABS is an interactive video-game
where a human player plays against a computer driven agent. The game runs
on SparcStations and starts up by displaying a game window and a control
panel window (figure ). The human player's plane is always
displayed in the center of the screen. The aerial two-dimensional position
of the enemy plane is displayed on the screen with the direction of flight
relative to the human player's plane. The human player looks at the game
screen to determine his airplane's position and orientation with respect to
the enemy's plane. (S)he then uses the control panel to choose a move. A
move is a combination of changing altitude, speed, and direction. When the
human player presses the go button, the computer agent also selects a move.
The game simulator then considers the human player's move and the computer
agent's move to determine the outcome of moves, and updates the screen and
the accumulated damage to planes. ABS simulates simultaneous moves this
way. If a player's plane is close in altitude and position to the enemy
plane, and the enemy is in frontal sight, the latter is fired on
automatically (i.e., firing is not a separate action). The levels of damage
are recorded in a side panel, and the game ends when one or both of the two
player's planes are destroyed.
The agent is developed in accordance with the principles of the GLAIR
architecture. Figure schematically represents its
structure.
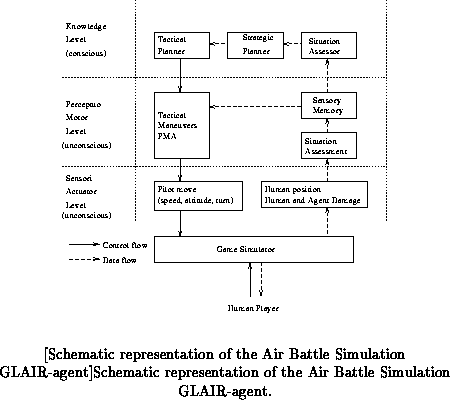
Initially, the agent has not acquired a PMA, and uses conscious level reasoning to decide what move to make. Once transitions are learned and cached in a PMA, the agent uses the PMA for deciding its next move whenever possible. By adding learning strategies, a PMA can be developed that caches moves decided at the Knowledge level for future use. Learning can be used to mark PMA moves that prove unwise and to reinforce moves that turn out to be successful. We are exploring these learning issues. We started ABS with an empty PMA and as the game was played, transitions of the PMA were learned. Also as the transitions were learned, when similar situations occurred and there was an appropriate PMA response, the PMA executed that action. As the game was played, we observed that the agent became more reactive since the PMA was increasingly used to generate behaviors instead of the Knowledge level.