Previous: Locating the Berlin and Kay Color Stimuli in the Color Space Up: From Color Space to Color Names
Next: Theoretical Evaluation of the Category Model
After choosing a category model and quantifying the data set, we now need
to fit the model to the data. I will describe a one-pass procedure to
accomplish this, but in principle it is also possible to ``learn'' the fit
incrementally, using one example at a time.
The problem is complicated by having a continuous-valued model (the
normalized Gaussian) but discrete data (member of the category or not,
focal example or not). We need to choose some threshold value to be
associated with the category boundaries, and another value to be associated
with the foci. Given our model it is natural to choose a value of unity
for the focus, and for the threshold value I have arbitrarily chosen
. After some experimentation, I have obtained the best results
with a fitting procedure that minimizes the following quantity
(independently computed for each category):
which is of course a sum squared error criterion. In
equation , E is the total sum squared error for a
particular category, composed of three separate terms. The first term
quantifies the error of fit with respect to the vertices of the bounding
polygon, with
representing the number of vertices,
the
normalized Gaussian function from equation
,
a boundary vertex vector
,
a linear scaling
vector for the initial focus
of the normalized Gaussian,
the ``width'' parameter of the normalized Gaussian, and
the threshold value for category membership, in our case equaling
. The second term quantifies the error of fit with respect to
the focal stimuli, with
representing a fixed weight for this error
term, set to
by trial-and-error
,
representing the number of focal stimuli (indicated by black dots in
Figure
),
a focal stimulus vector, and
the remaining symbols as in the first term. The third term quantifies the
error of fit with respect to other-category representatives, with
representing the number of other-category representatives,
a threshold
function (see below),
representing an other-category
representative
, and the other symbols as before.
The other-category representatives are collected by selecting from the
boundary or focus stimuli of each other category those that are closest (in
terms of Euclidean distance) to the initial focus of the current category
(see below), for each dimension separately. The union of the sets of such
stimuli over all dimensions becomes the set of other-category
representatives. It is necessary to select the nearest points in each
dimension separately, because the dimensions may be scaled independently in
a subsequent step. The threshold function T is defined as
The effect of using T in the third term is to create a horizon for
other-category representatives: as long as their function value for the
current category's model function is below some value , it is
not counted at all. I have used
. The minimization of
is carried out with respect to
and
(each
component independently) by Mathematica's standard FindMinimum function,
which finds local minima in a function by following the path of steepest
descent from any point it reaches. Loosely speaking, this amounts to moving
the focus of the model function (the normalized Gaussian) around in the
color space so as to bring the boundary stimuli's membership values as
close as possible to
, the focus stimuli's membership values as
close as possible to 1, and the membership values for any other category's
representatives below the horizon value
.
The use of other-category representatives in the error function may cause the category boundaries of a category to shift to some extent as a function of the distance, or presence or absence, of other categories nearby. There is some evidence in Berlin and Kay's work that the extent of categories may indeed be influenced by the total number of basic categories, and hence by their mutual distance, but I have not examined this any further.
Since the minima found by the FindMinimum function are local, the initial
values for the variables and
are quite important.
For the initial value of
I have used the identity scaling vector
, which combined with a value of
given by
(with representing the number of dimensions of the space, and
the
-th coordinate of focal stimulus
) places the initial
model focus at the center of gravity of the focal stimuli, and hence on or
near the OCS surface. In order to determine an initial value for
,
we find the same-category stimulus
(focal or boundary, but typically
boundary) that is farthest away from
as just defined (using Euclidean
distance in the color space), and then determine
such that
. Since the value of
the normalized Gaussian is a monotonic function of distance to the focus,
and
is the point in the set farthest away from the focus, any value
of
larger than (i.e. a ``wider'' curve) that will result in a
monotonically increasing square error over the complete set (for a constant
focus), and values smaller than that will lead to the nearest local
minimum. Even if this minimum is not the global one, this procedure will
ensure it is the ``same'' minimum for all categories. In principle the
error landscape as a function of
can have up to
local minima
for
points over which the error is computed. In practice the minimum
found in this way seems to be usually the global one, or at least very
close to it. Figure
illustrates this for the
1-dimensional case.

After determining the values of and
through error
minimization, a second minimization step is applied, which involves
distorting the Euclidean nature of the space. The first step used a
Euclidean distance metric, resulting in spheroid contours of equal
membership value. The second step allows the dimensions of the space to be
scaled individually for each category model, which can effectively results
in an non-spheroid contour of equal membership value (cf. the discussion of
Shepard's model in section
).
The procedure for this scaling involves an other
error minimization comparable to the first, with the objective function
defined by
which is basically the same as equation , but having both
data points and category foci scaled by the vector
, and
with
where
is the result of the first minimization step. The minimization is carried
out as before by Mathematica's FindMinimum function, with initial values
after the first minimization step, and
. Informally speaking, this amounts to stretching (or
compressing) the dimensions of each category to make it fit the data
better. Alternatively, one can think of it as stretching the dimensions of
the color space to make it fit the categories better, but locally only. The
obtained scaling vectors for the XYZ, L*a*b*, and NPP spaces are shown
in Figure
.

One way to interpret this figure is that the closer the vectors cluster to the main diagonal of the unit cube, the more Euclidean the space is (or the categories are), since that corresponds to spheroid surfaces of equal membership value. There are clear differences between the spaces in this respect, but there does not seem to be one ``best'' space in this respect.
The result of fitting the category models to Berlin and Kay's data for
(American) English, using the two-step method described above, is shown in
Figures to
. These figures show the locations of the
category centers (the values of
for each category model) only; the
boundaries will be discussed below.
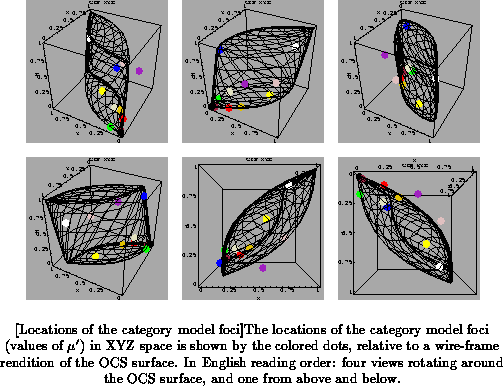
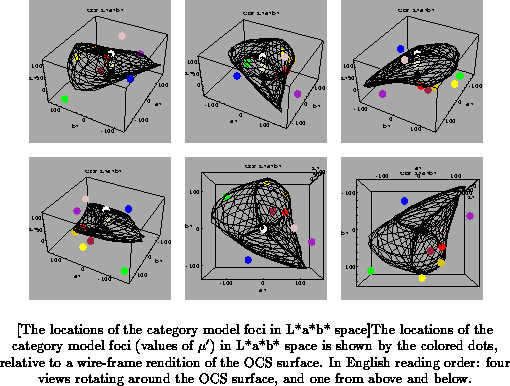
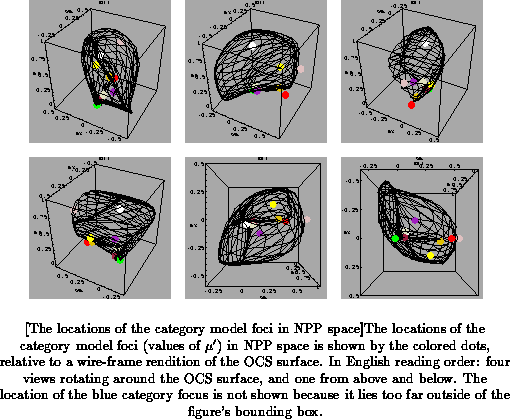
It is interesting to note that some of the foci lie outside of the OCS
volume, which means that they do not correspond to physically realizable
(and perceivable?) surface colors. Technically, this is the result of
allowing the foci to ``float'' in the first part of the fitting procedure.
While it is possible to constrain the foci to lie on or below the OCS
surface, that results in a considerably poorer fit, and degraded
performance for the algorithms using the category models, to be discussed
in Chapter . I am not sure what might
the the neurophysiological correlate of these ``virtual foci'', if any.